Introdução
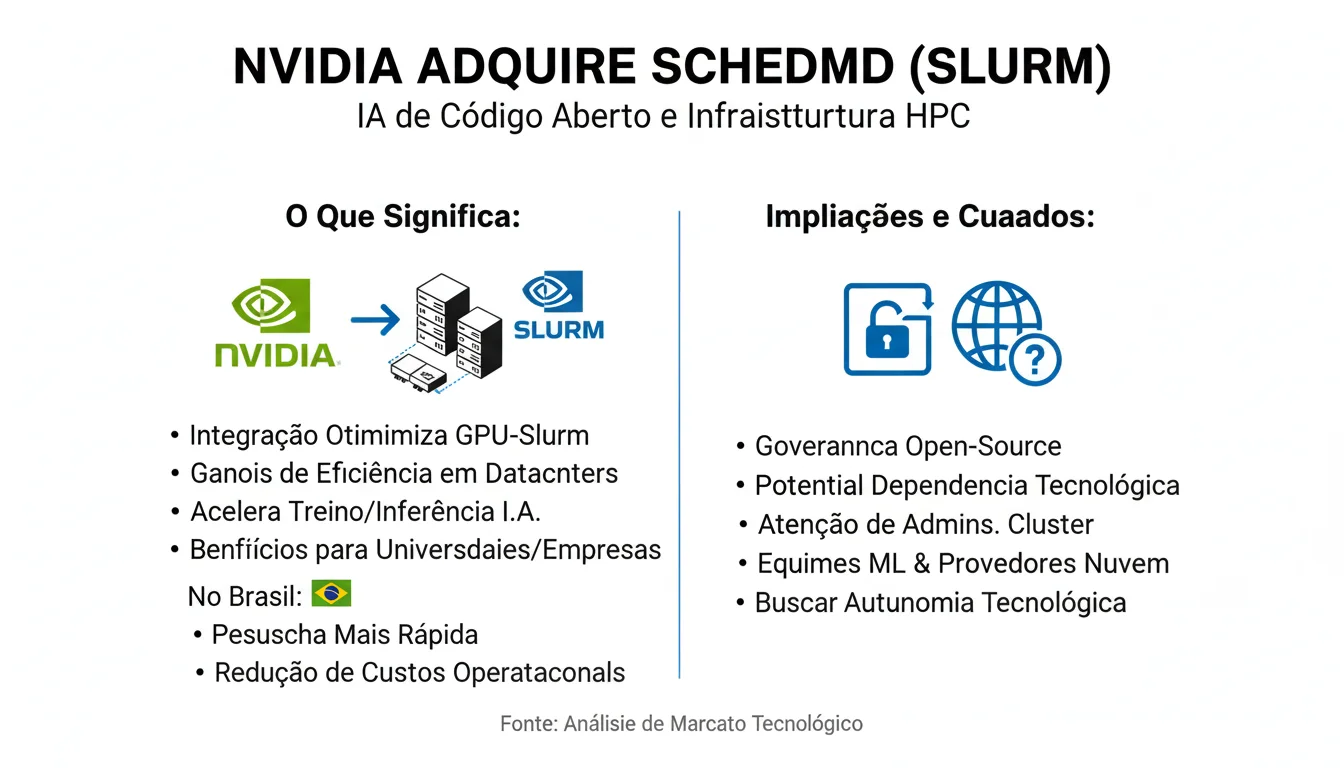
A recente aquisição da SchedMD pela Nvidia acendeu um novo capítulo na corrida por controle e otimização da infraestrutura que sustenta a inteligência artificial moderna. O movimento da fabricante de GPUs — protagonista incontestável no mercado de aceleradores para ML — vai além de chips: ele mira o software de orquestração de cargas que mantém clusters de alto desempenho funcionando de forma eficiente. Para profissionais de tecnologia e líderes de TI no Brasil, entender essa compra é entender um pouco do futuro operacional de treinos e inferência em escala.
A SchedMD é a principal mantenedora do Slurm, um gerenciador de cargas (workload manager) open-source usado amplamente em ambientes de computação de alto desempenho (HPC) e em muitos centros de pesquisa. Slurm coordena como jobs são alocados em nós, como GPUs são distribuídas entre tarefas e como o sistema lida com filas, prioridades e falhas — funções críticas quando se treina modelos grandes ou se executa inferência massiva. A chegada da Nvidia a esse ecossistema sugere uma estratégia para fortalecer suas iniciativas de software open-source e tornar o uso de suas GPUs ainda mais integrado e eficiente.
Neste artigo vamos destrinchar o anúncio, explicar tecnicamente o que o Slurm faz, contextualizar historicamente a importância do scheduler em ambientes HPC, analisar impactos práticos para datacenters e pesquisadores — com foco na realidade brasileira — e apontar possíveis cenários e tendências que nascem dessa união entre hardware e software de orquestração.
Dados e relevância do tema: a integração entre hardware e software tem se mostrado um diferencial competitivo na era da IA. Empresas que dominam tanto os aceleradores quanto as camadas de gerenciamento tendem a oferecer ganho de desempenho, menores custos operacionais e maior previsibilidade de entrega. Para o Brasil, onde investimentos em infraestrutura ML costumam ser mais seletivos, decisões arquitetônicas como essa podem afetar desde centros de pesquisa até startups que dependem de nuvem ou clusters locais.
Desenvolvimento
O que aconteceu: em um anúncio recente, Nvidia confirmou a aquisição da SchedMD, empresa conhecida por desenvolver e manter o Slurm. O comunicado destacou a intenção de ampliar a iniciativa de IA de código aberto e reforçar a pilha de software para computação de alto desempenho. Informações públicas sobre valores financeiros ou termos detalhados da transação não foram divulgadas no anúncio oficial, o que é comum em aquisições estratégicas de empresas privadas.
O papel do Slurm: tecnicamente, o Slurm (Simple Linux Utility for Resource Management) é um sistema de agendamento e gerenciamento de recursos para clusters. Ele oferece funcionalidades como agendamento por políticas, alocação de nós para jobs paralelos, gerenciamento de filas, preempção, contabilização de consumo e integração com sistemas de provisionamento. Para workloads de IA, o Slurm atua no ponto crítico de decidir como distribuir GPUs, quantas GPUs atribuir a cada treinamento distribuído e como coordenar jobs que exigem interconexão de alta velocidade entre nós.
Contexto técnico e histórico: historicamente, o HPC sempre dependeu de software de orquestração para extrair máximo desempenho de hardware caro. Com o advento da IA e dos modelos cada vez maiores, a complexidade de gerenciamento de recursos aumentou: agora não se trata apenas de CPU e memória, mas de alocação eficiente de GPUs, redes de alta velocidade (InfiniBand, por exemplo), e de suportar frameworks como TensorFlow, PyTorch e ferramentas de inferência. Slurm se consolidou por sua capacidade de escalar e por ser adotado em diversos grandes centros de pesquisa e supercomputação.
Implicações imediatas: a aquisição permite à Nvidia atuar diretamente na camada que gerencia quem usa as GPUs e como elas são usadas. Isso traz possibilidades práticas, como otimizações específicas para arquitetura de GPU, integração nativa com bibliotecas e drivers Nvidia, e potenciais melhorias na visibilidade e telemetria do uso de recursos. Para operadores de datacenter, isso pode significar ferramentas mais afinadas para reduzir o tempo ocioso de GPUs e aumentar a eficiência energética e de custo.
Consequências para pesquisadores e empresas: pesquisadores que rodem treinos grandes em clusters poderão se beneficiar de políticas de agendamento otimizadas para cargas ML, menor latência em comunicação entre nós e integração com ferramentas de monitoramento. Empresas que gerenciam pipelines de treinamento e inferência — inclusive provedores de nuvem e integradores no Brasil — podem ter acesso a soluções mais integradas, o que reduz esforço de customização e acelera a entrega de projetos.
Exemplos práticos: imagine uma universidade brasileira que opera um cluster com GPUs para grupos de pesquisa em processamento de linguagem natural. Com uma integração mais estreita entre Slurm e o ecossistema Nvidia, a equipe de infraestrutura pode definir agendamentos que priorizem treinos críticos, isolar recursos por projeto e usar métricas precisas para cobrar ou balancear custos entre grupos. Em provedores de nuvem ou empresas de MLOps, a capacidade de alocar GPUs com granularidade e visibilidade pode reduzir latência em inferência em produção e diminuir custos por job.
Perspectiva de especialistas e análises: analistas de infraestrutura costumam apontar que controle sobre a pilha completa — do silicium ao scheduler — tende a gerar ganhos de desempenho significativos. Ao mesmo tempo, há discussões legítimas sobre governança do open-source: quando um player dominante se torna mantenedor de um componente crítico, surge a necessidade de transparência e compromissos com a comunidade para evitar decisões que favoreçam somente um fornecedor. Comunidades open-source em HPC historicamente valorizam neutralidade e interoperabilidade.
Riscos e pontos de atenção: uma aquisição dessa natureza levanta questões sobre compatibilidade multi‑vendedor. Operadores que utilizam GPUs de outros fabricantes ou infraestruturas heterogêneas vão observar se o Slurm continuará neutro e aberto no desenvolvimento. Outro ponto é a dependência: organizações brasileiras que se apoiarem nas otimizações Nvidia precisarão avaliar impactos de lock-in versus ganhos operacionais.
Tendências relacionadas: a peça se encaixa em uma tendência maior de consolidação entre hardware e software. Vemos empresas investindo em acelerar a pilha de IA como serviço, seja por meio de parcerias com provedores de nuvem, compra de capacidade ou aquisição de camadas de software críticas. Ademais, o foco em open-source por parte da Nvidia indica esforço em liderar padrões de fato — um movimento que pode estimular maior padronização ou, alternativamente, competição entre stacks proprietários e abertos.
O que esperar no curto e médio prazo: esperam-se updates no roadmap do Slurm com melhorias para workloads de IA e integração com ferramentas de telemetria e orquestração de containers. Administradores de clusters e equipes de engenharia de ML devem acompanhar releases e comunicados da SchedMD para planejar migrações ou adoção de novas funcionalidades. No mercado, é provável que surjam soluções comerciais que combinem o Slurm otimizado com serviços de suporte e integração oferecidos por Nvidia ou parceiros.
Conclusão
Em resumo, a compra da SchedMD pela Nvidia é um movimento estratégico que reforça a importância do software de gerenciamento de cargas na era da IA. A incorporação do desenvolvimento do Slurm por um fornecedor de hardware visa reduzir atritos entre o uso das GPUs e o software que as gerencia, potencialmente gerando ganhos de eficiência e redução de custos operacionais para operadores de cluster e provedores de serviços.
O futuro próximo deverá trazer novidades técnicas e comerciais: melhorias em integração, novas ferramentas de observabilidade e, possivelmente, pacotes de serviços que unam hardware Nvidia, otimizações de scheduler e suporte profissional. Para a comunidade open-source, o desafio será manter a governança e a interoperabilidade, garantindo que inovações beneficiem um ecossistema amplo e não apenas um ator dominante.
Para o Brasil, a aquisição pode representar uma oportunidade e um alerta. Instituições de pesquisa, startups e provedores locais podem se beneficiar de uma pilha mais integrada para acelerar projetos de IA, mas também precisarão avaliar riscos de dependência tecnológica e negociar estratégias multi‑provedor quando necessário. Em um cenário ideal, a movimentação resulta em maior produtividade e em redução do custo por experimento — fatores cruciais para avanço de P&D no país.
Se você gerencia infraestrutura, é hora de revisar roadmaps e preparar times para updates; se é pesquisador ou desenvolvedor, acompanhe os próximos releases do Slurm; e se atua em negócios que dependem de IA, avalie como uma pilha mais integrada pode alterar custos e prazos de entrega. A aquisição marca mais um passo na maturação da infraestrutura de IA — e seu efeito prático dependerá de como fornecedores, comunidades e clientes brasileiros reagirem a essa nova configuração do ecossistema.