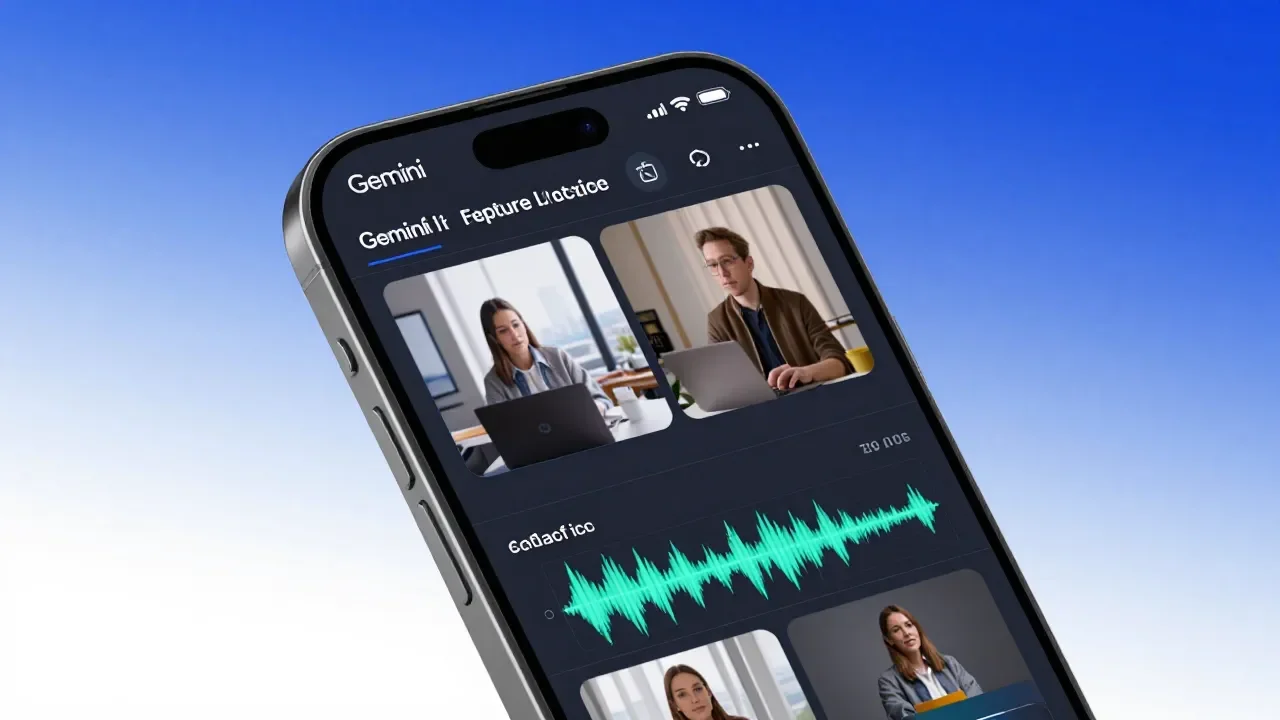
O Google DeepMind apresentou o Gemini Omni, um modelo de inteligência artificial multimodal capaz de criar e editar vídeos a partir de comandos em linguagem natural, combinando texto, imagem, áudio e vídeo em um único fluxo de trabalho. A tecnologia foi revelada durante o Google I/O 2026, realizado em 19 de maio, e já está disponível em plataformas como o aplicativo Gemini, o Google Flow e o YouTube Shorts. O modelo representa uma evolução significativa na geração de conteúdo audiovisual por IA, ao unificar diferentes tipos de mídia em uma única interface conversacional.
A primeira versão liberada, chamada Gemini Omni Flash, é descrita pela empresa como um modelo do tipo any-to-any, ou seja, capaz de receber qualquer combinação de entradas — texto, fotos, áudio ou vídeo — e gerar qualquer tipo de saída a partir dessas referências. O modelo utiliza raciocínio sobre o mundo real, incluindo noções de física, movimento e causalidade, para produzir vídeos com maior naturalidade e coerência.
A principal proposta do Gemini Omni é eliminar a necessidade de ferramentas separadas para cada etapa da produção audiovisual. Em vez de alternar entre editores de imagem, software de áudio e programas de montagem de vídeo, o usuário interage com o modelo por meio de uma interface conversacional, enviando comandos em texto, voz ou imagem. O sistema mantém o contexto ao longo de várias interações, permitindo ajustes sucessivos sem perda de consistência.
O Gemini Omni aceita até cinco fotos como referência visual para garantir a fidelidade e a continuidade das cenas geradas. É possível solicitar a troca de personagens, a mudança de iluminação, o ajuste de fundos, a substituição de objetos e a alteração de figurinos apenas com instruções simples em linguagem natural. O modelo também gera áudio nativamente, acompanhando as demais mídias de forma integrada.
A consistência visual e espacial é um dos pontos centrais da tecnologia. Manter personagens, objetos e cenários coerentes ao longo de múltiplas edições é um dos desafios mais conhecidos da geração de vídeo por IA. O Gemini Omni utiliza conhecimento de mundo real e princípios de física para preservar proporções, sombras, iluminação e continuidade mesmo após diversas alterações, sem que o usuário precise reiniciar o projeto do zero.
Na prática, o modelo já está sendo utilizado para a criação rápida de conteúdo no YouTube Shorts, onde permite remixar vídeos elegíveis a partir de texto, imagens, áudio e vídeo como entrada. O Google Flow, plataforma de criação do ecossistema Google, recebeu ferramentas adicionais integradas ao Gemini Omni Flash, como o Flow Agent, voltado para brainstorming e geração em lote, além de recursos sem código para otimizar videoclipes e estilos musicais.
Para garantir a procedência do material gerado, o Google incorpora tecnologias de autenticação como SynthID — um sistema de marcação invisível para conteúdo produzido por IA — e o padrão C2PA, que registra a origem e o histórico de modificações de arquivos digitais. Essas medidas visam atender à crescente demanda por transparência na produção de conteúdos sintéticos.
Em comparação com o Veo, modelo anterior do Google para geração de vídeo, o Gemini Omni adota uma arquitetura unificada. Enquanto o Veo utiliza modelos separados para cada tipo de mídia, o novo modelo integra todas as modalidades em um único sistema contínuo, evitando problemas de inconsistência que surgem na transição entre ferramentas distintas. Essa abordagem permite edição multi-turno, na qual o usuário pode refinar o resultado em várias etapas dentro da mesma conversa.
Demis Hassabis, cofundador da DeepMind e responsável pela área de IA do Google, descreveu o Gemini Omni como um modelo de mundo, destacando sua capacidade de simular contextos reais com alto nível de detalhamento. Estudos iniciais da própria empresa indicam que o modelo supera concorrentes em fidelidade visual e continuidade, com maior coerência em vídeos longos e melhor adaptação a comandos variados.
Especialistas apontam que o Gemini Omni pode acelerar o processo criativo em até 50% para profissionais de vídeo e produtores de conteúdo. A redução da complexidade técnica — especialmente a eliminação da necessidade de operar timelines e camadas manuais — permite que criadores foquem mais na concepção das ideias do que na execução operacional.
A chegada do Gemini Omni reforça a disputa entre grandes empresas de tecnologia pelo domínio da IA generativa multimodal. Enquanto a OpenAI avança com modelos como o GPT-4o e o Sora para geração de vídeo, e a Anthropic expande as capacidades do Claude, o Google consolida sua estratégia ao integrar o novo modelo diretamente em seus produtos de consumo, como o YouTube e o ecossistema de aplicativos Gemini.
A disponibilização imediata do Gemini Omni Flash em plataformas de amplo acesso sugere que o Google pretende escalar a adoção da tecnologia rapidamente. A integração com o YouTube Shorts, em particular, coloca a ferramenta ao alcance de milhões de criadores de conteúdo que já utilizam a plataforma, sem necessidade de conhecimento técnico avançado em edição de vídeo.
O lema do projeto — Create anything from any input, starting with video — resume a ambição do Google DeepMind: transformar qualquer tipo de entrada em conteúdo audiovisual coeso, a partir de uma conversa. Com o Gemini Omni, a empresa dá um passo significativo rumo à unificação das ferramentas de criação multimodal, em um cenário onde a velocidade e a facilidade de produção tendem a se tornar fatores competitivos cada vez mais relevantes.





