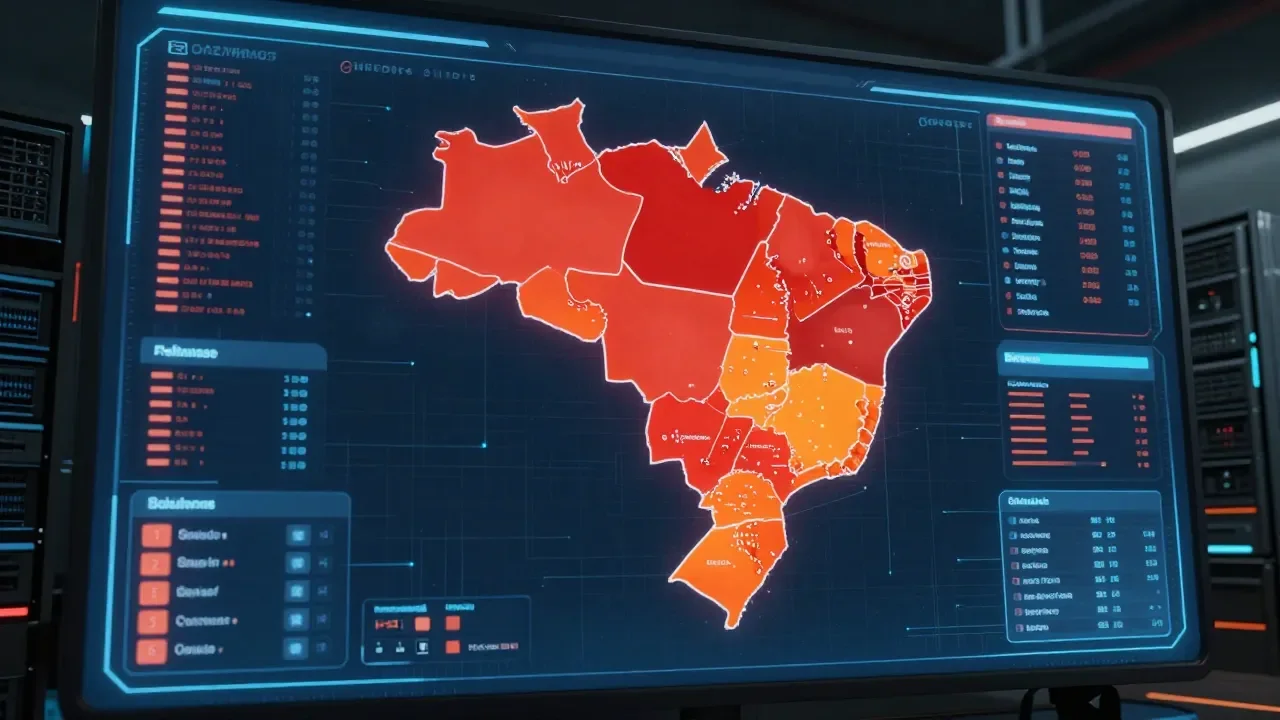
Um estudo acadêmico conduzido pela Universidade de Oxford expôs uma falha crítica no funcionamento de modelos de linguagem de grande porte, demonstrando como ferramentas de inteligência artificial podem reproduzir e amplificar preconceitos regionais no Brasil. A pesquisa analisou o comportamento do ChatGPT ao ser solicitado a classificar os estados brasileiros com base em critérios como inteligência, governança e desenvolvimento. Os resultados indicaram uma clara tendência da plataforma em favorecer regiões do Sudeste e Sul, ao passo que desvalorizou áreas do Norte e Nordeste, evidenciando que os algoritmos de geração de texto, embora complexos, não operam com neutralidade.
A relevância deste tema reside na ubiquidade dessas ferramentas, que se tornaram fontes primárias de informação para milhões de usuários em todo o mundo. Quando um sistema de inteligência artificial automatiza juízos de valor sobre grupos populacionais, ele corre o risco de legitimar estereótipos sob uma camada de autoridade técnica. O estudo, intitulado O Olhar de Silício, aponta que o problema não é inerente à tecnologia em si, mas sim aos vastos conjuntos de dados utilizados para o treinamento dos modelos. Como esses dados são extraídos majoritariamente de conteúdos disponíveis na internet, eles refletem as desigualdades, visões de mundo e preconceitos enraizados historicamente na sociedade.
Para entender esse fenômeno, é preciso compreender que o treinamento de modelos de linguagem envolve o processamento de bilhões de palavras extraídas de textos diversos. Durante esse processo, a inteligência artificial aprende a prever a próxima palavra mais provável em uma sequência, baseando-se em padrões estatísticos. Se a fonte desses dados contém desequilíbrios na forma como diferentes regiões do Brasil são descritas, o modelo tenderá a reproduzir essa assimetria. Assim, o que o usuário percebe como uma análise inteligente é, na realidade, um reflexo estatístico dos vieses contidos nas fontes de informação acessadas pela máquina.
O levantamento demonstrou que o Distrito Federal e São Paulo foram classificados pela ferramenta como os estados com populações mais inteligentes. Em contraste, a plataforma atribuiu adjetivos negativos a estados do Norte e Nordeste, desconsiderando a complexidade social e econômica dessas regiões. O estudo também pontuou que o Rio de Janeiro enfrentou um tratamento diferenciado, sendo frequentemente rotulado sob critérios de desordem ou corrupção, o que exemplifica como a inteligência artificial pode atuar de forma simplista ao interpretar dados sobre unidades da federação. Esse padrão de resposta não reflete indicadores objetivos de educação ou competência, mas sim uma reprodução acrítica de estigmas culturais.
No campo da tecnologia da informação, o conceito de viés algorítmico refere-se justamente a essa distorção. Profissionais da área apontam que as empresas de tecnologia têm enfrentado dificuldades técnicas significativas para contornar esse problema. Uma vez que o modelo é treinado, ele carrega consigo uma bagagem informativa vasta, tornando difícil identificar cada instância na qual uma resposta pode conter um juízo de valor distorcido. A transparência no desenvolvimento desses sistemas tem sido uma demanda constante da comunidade científica, buscando que os processos de filtragem de dados sejam mais rigorosos e diversificados.
A comparação com outros atributos pesquisados, como a sociabilidade dos habitantes, revelou resultados curiosos que reforçam a natureza subjetiva da IA. Enquanto estados do Sudeste foram elogiados por atributos associados à inteligência, Minas Gerais obteve a melhor nota na categoria de facilidade para se fazer amigos. Essa segmentação de características humanas pela inteligência artificial ilustra como o sistema tenta classificar personalidades regionais com base em generalizações. Tais classificações são, por natureza, reducionistas e falham em captar a diversidade de comportamentos encontrados dentro de um mesmo estado.
Para o mercado brasileiro, o impacto de tais resultados é significativo. Empresas de tecnologia, agências de marketing e instituições educacionais que dependem de ferramentas de automação para análise de dados ou criação de conteúdo precisam estar atentas à possibilidade de que esses vieses interfiram em decisões estratégicas. O uso indevido de respostas automatizadas sem a devida revisão humana pode resultar na perpetuação de práticas excludentes ou na propagação de narrativas que prejudicam o desenvolvimento igualitário das regiões. A cautela no consumo dessas respostas é, portanto, essencial para evitar o reforço de estigmas regionais no ambiente digital.
Do ponto de vista técnico, a mitigação desses preconceitos exige o que os pesquisadores chamam de curadoria de dados especializada. Isso implica não apenas aumentar a quantidade de textos utilizados no treinamento, mas garantir que o conjunto de dados seja representativo e equilibrado, incluindo perspectivas de grupos que historicamente possuem menor visibilidade na rede. O monitoramento contínuo das respostas geradas e a implementação de filtros que identifiquem termos associados a estereótipos regionais são passos que já vêm sendo testados, embora ainda se mostrem insuficientes diante da complexidade da linguagem humana.
A discussão sobre inteligência artificial no Brasil ganha novos contornos com esse estudo. Não se trata apenas de debater a eficácia tecnológica, mas de questionar o papel ético dessas corporações no impacto social que seus algoritmos exercem. O fato de uma ferramenta ser capaz de categorizar estados com base em preconceitos regionais demonstra que a IA ainda se encontra em um estágio de amadurecimento, onde a precisão técnica não garante a isenção de julgamentos morais. A sociedade, os desenvolvedores e os órgãos reguladores possuem, cada um, uma parcela de responsabilidade nessa transição tecnológica.
O futuro das interações entre humanos e sistemas inteligentes dependerá da evolução dessas ferramentas para além dos padrões estatísticos. A busca por modelos que consigam compreender o contexto e a nuance, evitando a simplificação de fenômenos sociais, é um dos maiores desafios atuais. Enquanto isso não ocorre, o papel do usuário permanece fundamental na verificação da procedência e da imparcialidade dos conteúdos gerados, sendo o pensamento crítico a principal barreira contra a automatização de preconceitos.
A conclusão do estudo serve como um alerta necessário. A percepção de inteligência ou competência atribuída por uma máquina não deve ser confundida com uma medida absoluta de realidade. O cenário tecnológico atual, embora promissor, ainda carrega consigo as sombras do passado, processadas e replicadas pela velocidade dos algoritmos. A consciência sobre esses limites é o primeiro passo para garantir que a inteligência artificial sirva como uma ferramenta de progresso inclusivo e não como uma nova forma de exclusão digital e social.
Em síntese, o trabalho da Universidade de Oxford evidencia que a inteligência artificial reproduz as imperfeições da sociedade que a alimenta. Ao classificar estados brasileiros com critérios arbitrários, o sistema expôs a fragilidade dos seus próprios mecanismos de avaliação ética. Esse desdobramento reforça que o desenvolvimento tecnológico deve caminhar lado a lado com a responsabilidade social, exigindo maior transparência e diversidade na construção de sistemas que moldarão o futuro da informação no Brasil. O setor de tecnologia deve, portanto, encarar esse desafio como uma prioridade para evitar que inovações acabem por aprofundar divisões históricas.